How to use Fujitsu AutoML
Fujitsu AutoML provides two modes that differ in specifying dataset: Tutorial mode using the sample dataset and App mode using your own dataset. Please read the Terms of Use and accept it beforehand, and click either the two below buttons. By clicking on the button, you agree to the Terms of Use.
In this page, we will describe the usage of Fujitsu AutoML in the Tutorial mode.
Flow (table of contents)
- Specify dataset and machine learning requirements
- Run code generation
- Explore the results
- Run predictions on the model built with the generated code
1.Specify dataset and machine learning requirements
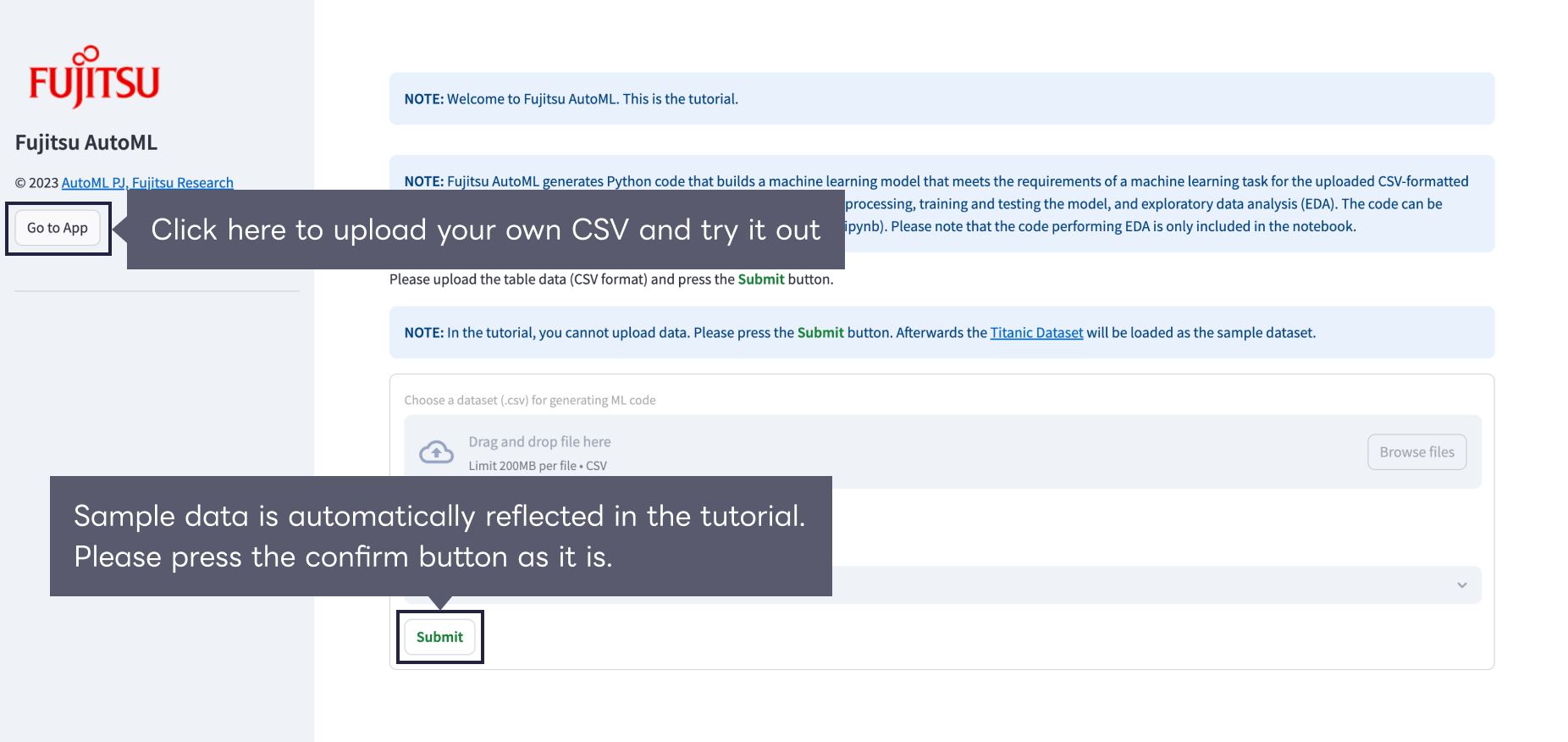
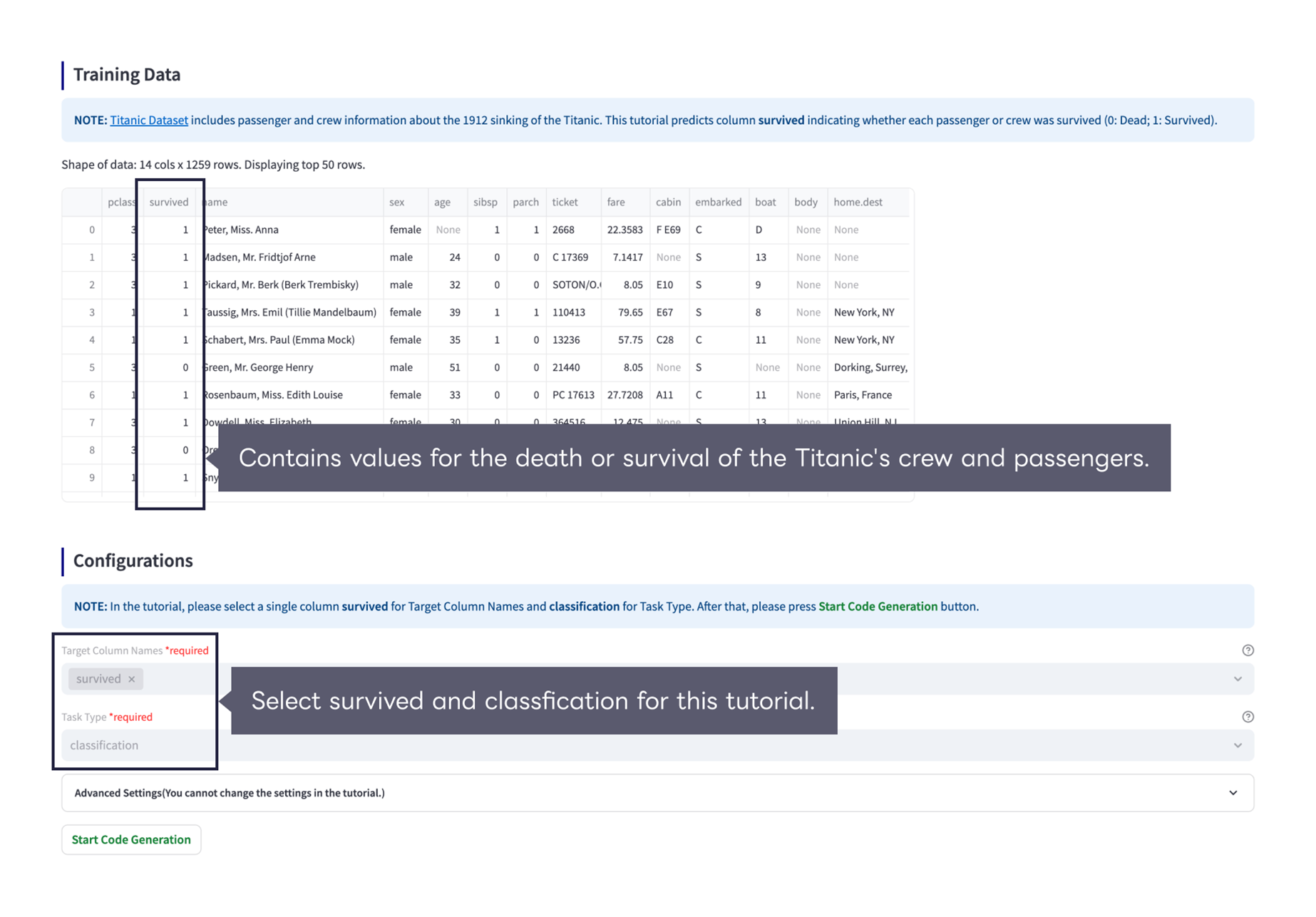
There are two ways in specifying dataset: Tutorial mode using the sample dataset by just clicking “Submit” button and App mode using your own dataset. After uploading the dataset, you will see a preview of the training data and the machine learning requirements settings.
Please click “Go to App” button located at the left menu if you want to try App mode
Here are the descriptions of each item in the machine learning requirements.
Target variable
(Required item) Select the column name that you want the machine learning task to predict.
Task type
(Required item) Select either classification or regression as the machine learning task type. Fujitsu AutoML automatically suggests a plausible task type after selecting the target variable by analyzing the actual values.
Column not used for training
Select the column names you want to ignore when training the machine learning model.
Evaluation index
Select an evaluation metric to evaluate your machine learning model. The selectable evaluation metrics are as follows.
- classification → F1, AUC, Accuracy, Gini, LogLoss, ROC_AUC, MCC
- regression → R2, RMSLE, RMSE, MAE
Timeout
Specify the timeout for one code execution when evaluating the model built by actually executing the machine learning program generated by Fujitsu AutoML.
Random seed
Specifies a seed for random number generation.
Percentage of training data when splitting data
Fujitsu AutoML internally divides the specified dataset into learning data and test data, and specifies the ratio of learning data at that time.
Hyperparameter search
By checking “Enable”, the code for hyperparameter search of the model is included in the generated code. When hyperparameter search is enabled, please set the “number of trials” and “random seed”.
Data description
Include code such as Exprolatory Data Analysis (EDA) in the generated code.
Please note that “Calculate Permutation Feature Importance” will be skipped even if it is checked, as it will take an enormous amount of time if the number of columns in the dataset exceeds 100.
2.Run code generation
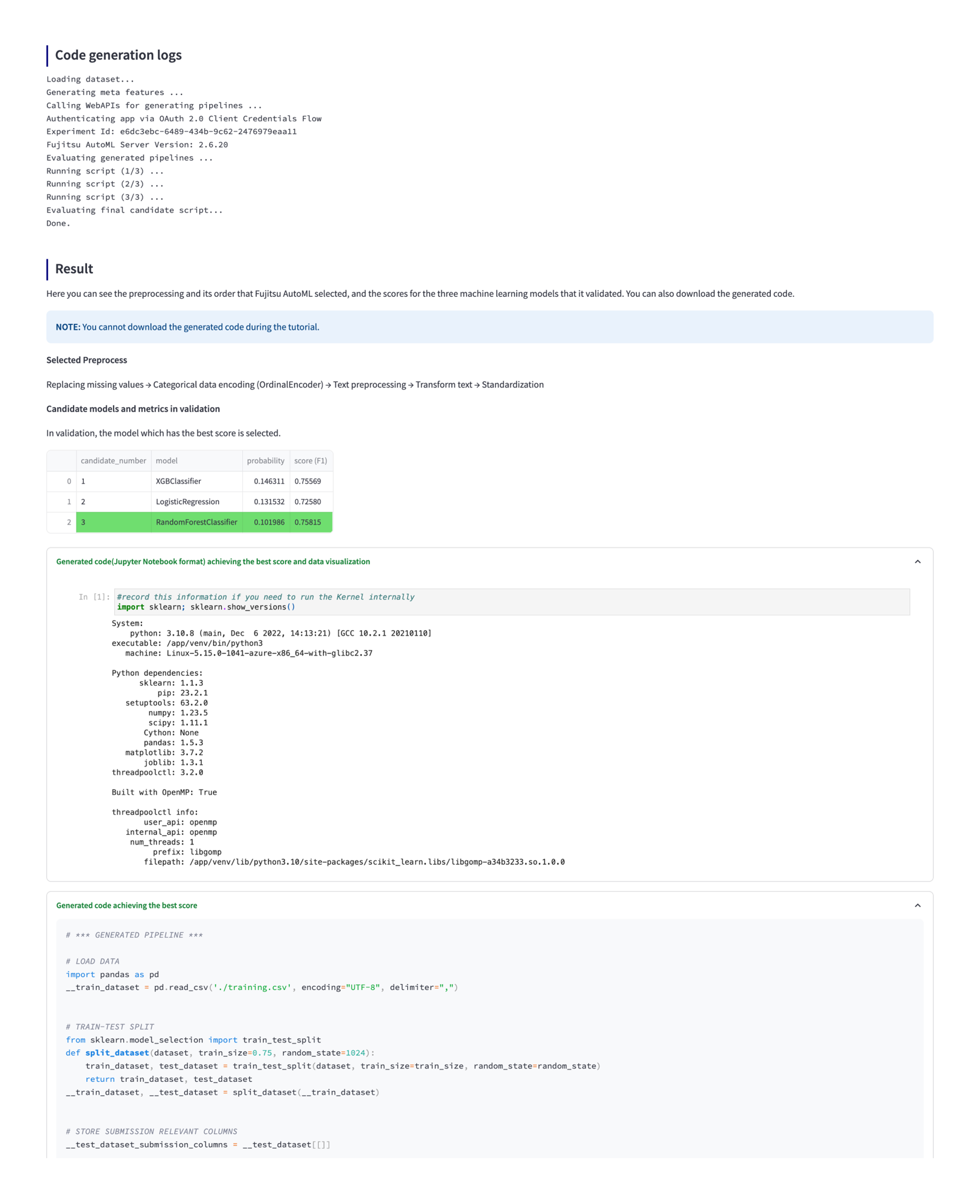
After specifying dataset and machine learning requirements, please click “Start Code Generation”. The execution time varies greatly depending on the size of the dataset and the contents of the parameters. In the code generation result, you can see the selected preprocessing and its order, the top 3 machine learning model candidates and the score at the time of verification. Fujitsu AutoML selects the model with the best score at the time of verification and outputs the generated code accordingly. Directly below the generated code with the best score is the “Download Generated Code” button. By clicking this, you can download a notebook both in the Python format (.py) and in the Jupyter Notebook (.ipynb) format, and a zip file that includes code for model learning and prediction.
Note: EDA is included in the .ipynb only.
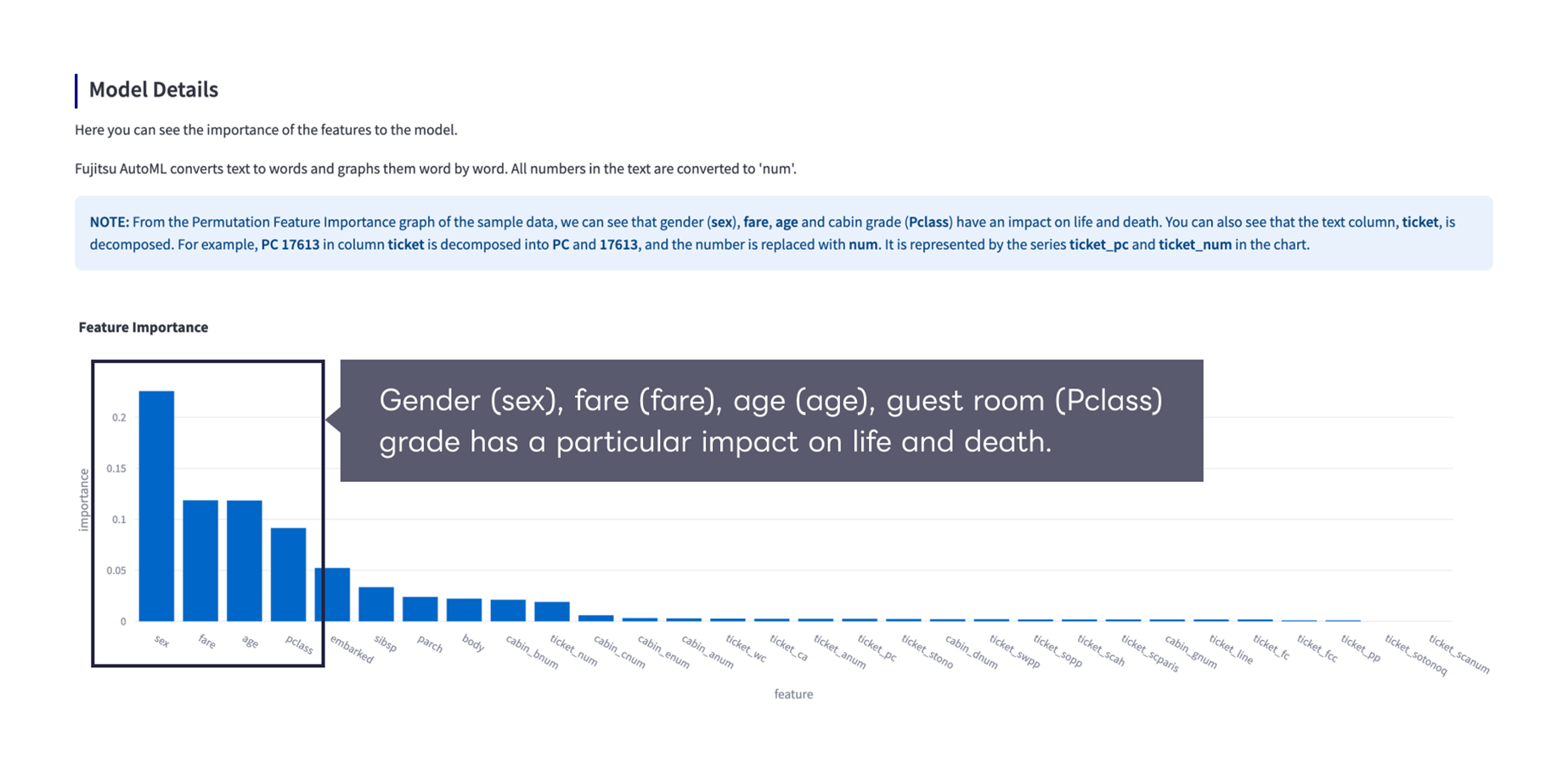
3.Explore results
Below the code generation results, Fujitsu AutoML visualizes the importance of features for the model and the relationship between the objective variable and the features.
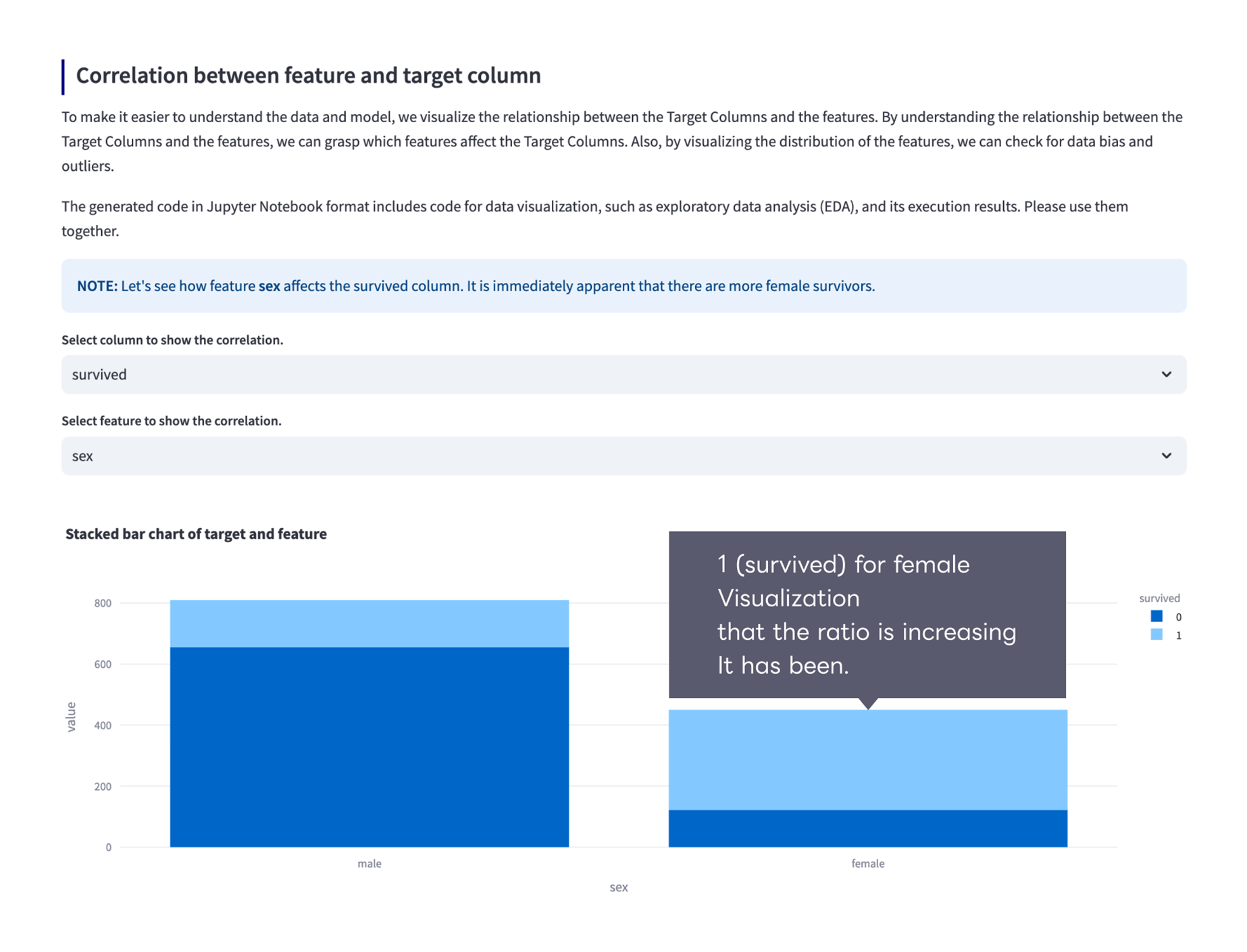
4.Run predictions using the model built with the generated code
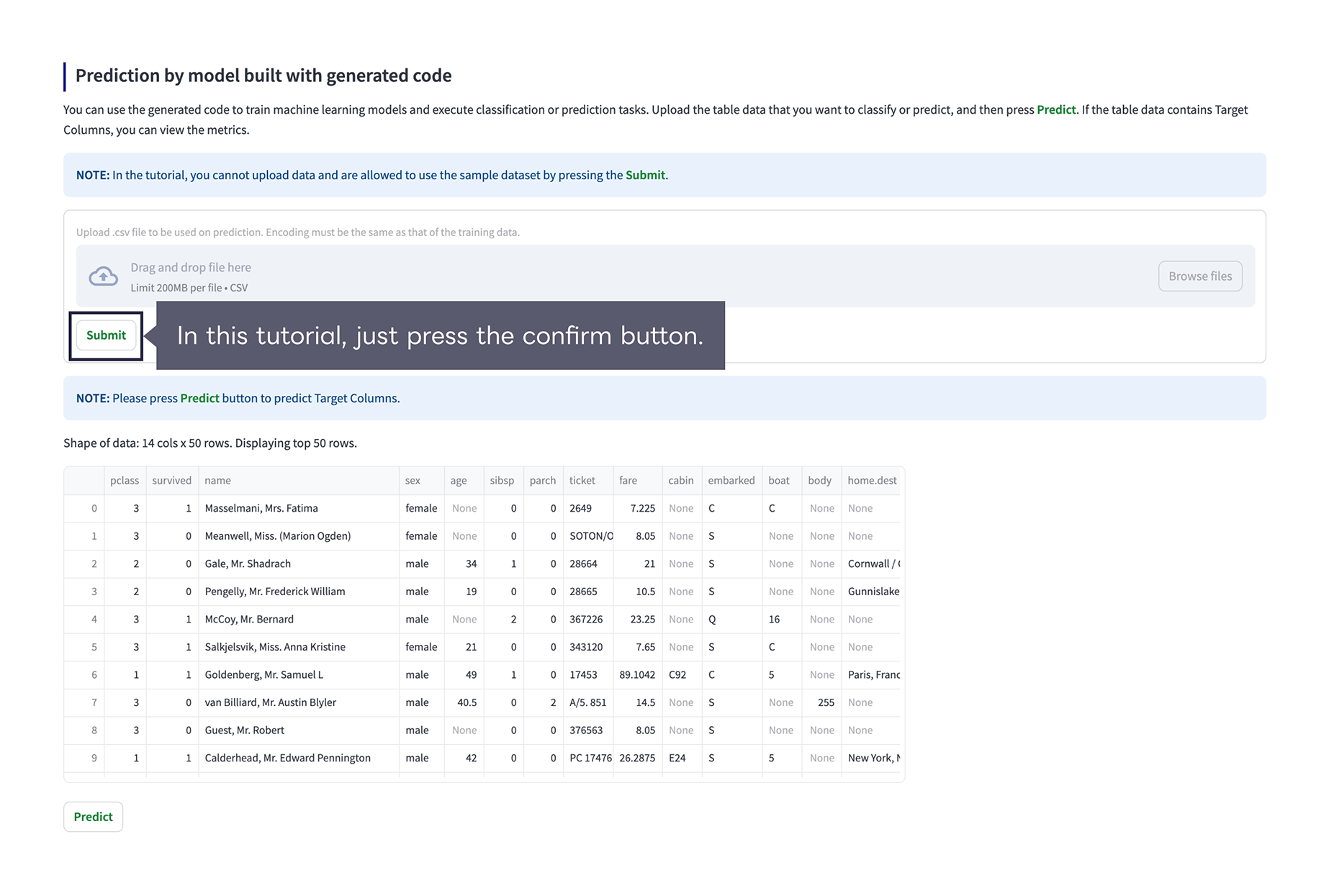
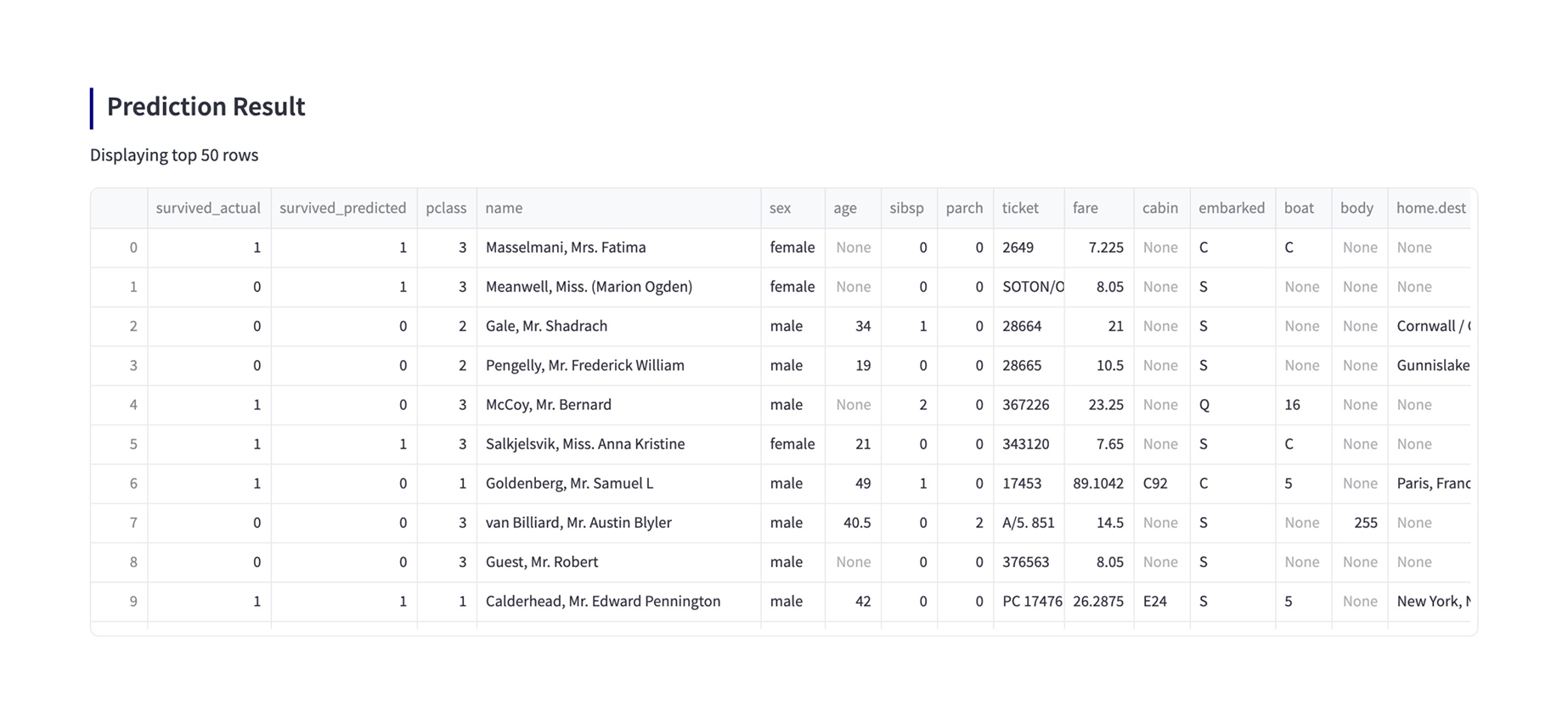
Finally, you can use the model built with the generated code to make predictions. Please upload the data to predict as well as the training data. If you used a sample dataset, click “Submit” button. Afterwards, please click the “Predict” button below the preview of the data to predict to start running the prediction and see the prediction results and metrics.

We can offer a trial of Fujitsu AutoML in a customer’s environment. It is also possible to consider specific use cases and requirements for customer business applications. Please contact us for details.